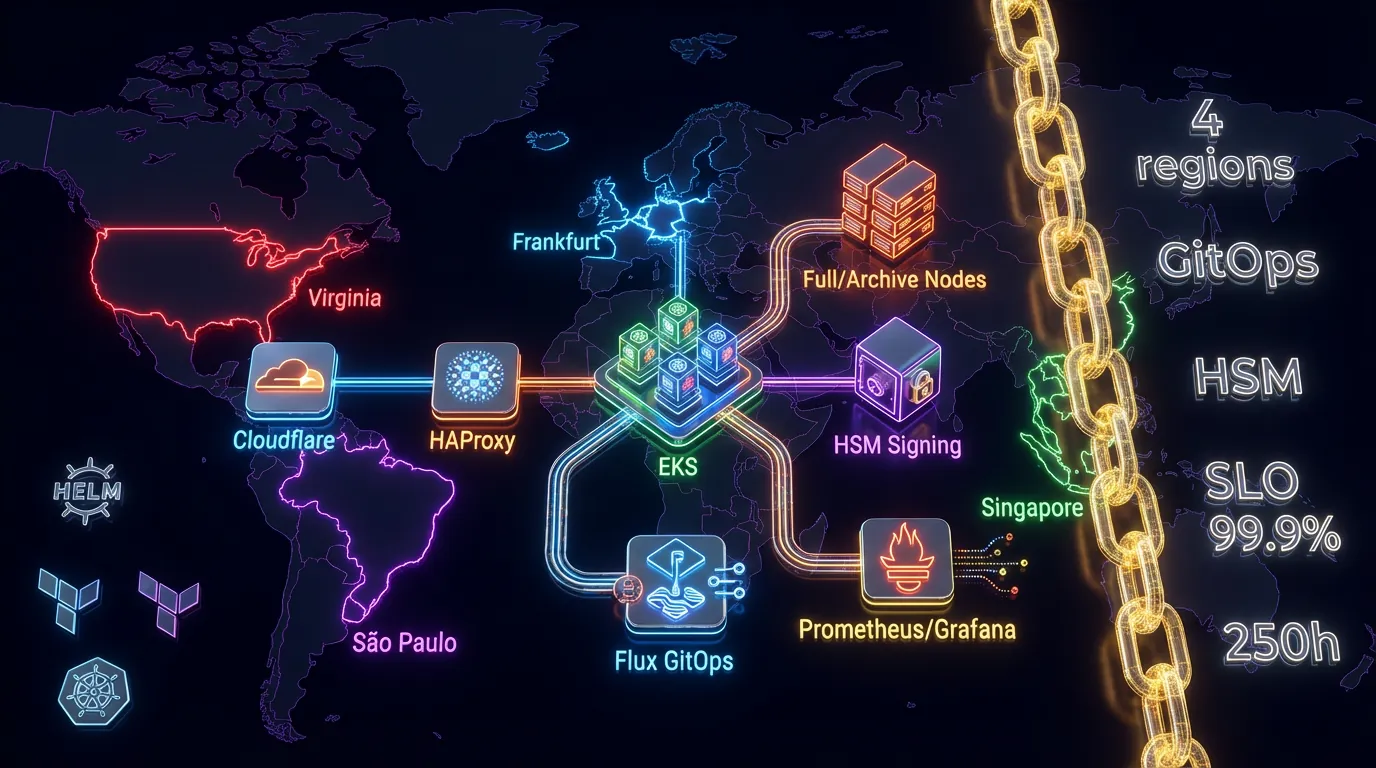
Геораспределённый кластер блокчейн-нод в Kubernetes
Геораспределённый кластер блокчейн-нод в Kubernetes Клиент Криптовалютная платформа (Web3 / DeFi)
Задача Клиенту требовалась отказоустойчивая инфраструктура для запуска ETH и BSC full-нод в четырёх регионах (EU, US, AP, LatAm) с минимальной задержкой для конечных пользователей, защитой от DDoS и спама на RPC, безопасным HSM-подписанием транзакций и централизованным мониторингом. Синхронизация нод с нуля занимает 2–3 недели — требовалось решение для быстрого старта.
Решение 1. Инфраструктура и IaC (Terraform + EKS) Terraform-модули: VPC, subnets, security groups для 4 регионов (Frankfurt, Virginia, Singapore, São Paulo) Managed Kubernetes (EKS 1.29+) per region с выделенными node pools: full nodes, archive nodes, signing service NVMe StorageClass (gp3) через CSI-драйвер для высокопроизводительного хранения chaindata Helm chart для geth / bsc-node с кастомными values per region 2. GitOps: Flux CD multi-cluster Flux CD v2 с Kustomization per region — единый источник истины для всех кластеров Secrets management: HashiCorp Vault + External Secrets Operator (ESO) Изменения в инфраструктуре применяются через git push без прямого доступа к кластерам 3. Балансировка и Anti-Spam HAProxy 2.8: sticky sessions, health checks по eth_syncing — трафик только к синхронизированным нодам Nginx Ingress: rate limiting, IP reputation filtering (Lua-скрипты в стиле fail2ban) Cloudflare Workers: geo-routing + защита от DDoS L7 Custom sidecar (Go): health endpoint, который возвращает ready только при полной синхронизации ноды 4. HSM-интеграция для подписания транзакций AWS CloudHSM (prod) / YubiHSM2 (staging) для хранения приватных ключей Go-микросервис с PKCS#11 абстракцией — смена HSM-вендора без переписывания кода Изолированный K8s namespace + NetworkPolicy: нет egress кроме HSM endpoint gRPC API для backend: sign tx, get pubkey Аудит-лог всех операций подписания → Loki 5. Мониторинг и алертинг Custom Prometheus exporter (Go): eth_blockNumber, eth_syncing, peer count per node Grafana dashboards: sync lag, block height per region, RPC latency, SLO 99.9% Alertmanager → PagerDuty: алерты на block lag > N блоков, node down, peer count < threshold Loki + Promtail: структурированные логи всех нод с корреляцией по region/pod 6. Операционка и Disaster Recovery Snapshot bootstrap: chaindata из S3 через rclone — нода готова за часы вместо недель DR playbook: пошаговые runbook’и для восстановления региона Chaos Engineering (Chaos Mesh): тесты на node kill, network partition, pod failure Architecture Decision Records (ADR) для всех ключевых решений Технологии